PDFspy is the ultimate “get info” utility for your PDF documents. It can extract a comprehensive list of attributes from a PDF file into an XML-based format.
Some examples of the many types of information PDFspy can extract:
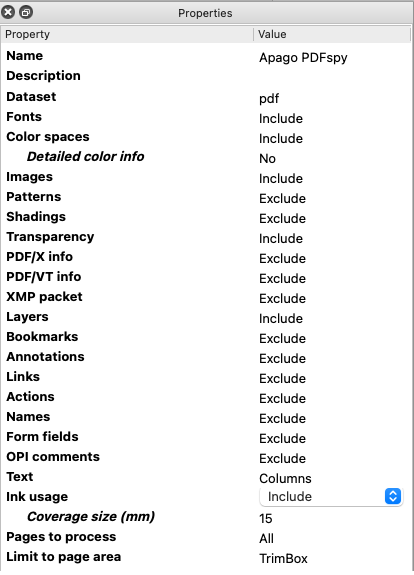
Page information (count, size, boxes)
Fonts usage (name, type, embedding & subset status, use of Unicode)
Color info including colorspaces, separations marked and ink usage and coverage calculations
Images (size, resolution, compression, colorspace)
Text in raw (.txt), reconstructed words, lines, paragraphs and columns
Use of transparency, smooth shadings and patterns
Presence (or absence) of hidden text and optional content/layers
Hyperlinks (size, location and destination)
Annotations (size, location, type, contents, colors)
PDF/X compliance (including output intent details)
Metadata (info dictionary & XMP)
Security and Encryption settings
Example uses:
Order management system: compare customer files to order specifications
Asset management system: extract page count, metadata, font & image information
Document management: determine text or image only documents, extract comments
Preflight: extract information about colorspaces, compression & font types
Developers: easily examine the structure of complex PDF documents
NOTE: This app requires that Apago PDFspy be installed and licensed. Download PDFspy from https://www.apagoinc.com/product/pdfspy/
![]()
© 2025 Enfocus, an Esko company Visit Enfocus.com
